🚀 Benchmark de librerías para análisis de datos en Python#
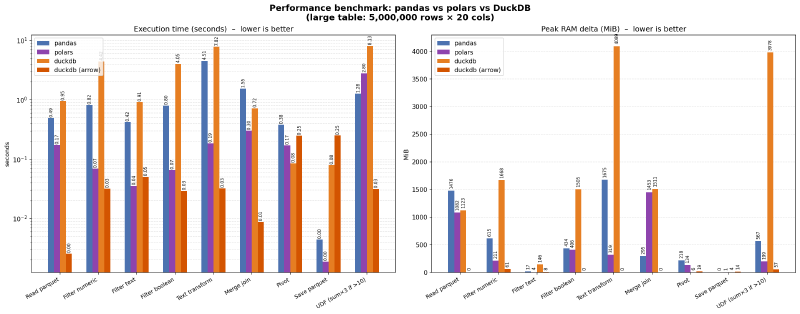
Comparé el rendimiento de Pandas 3.0, Polars y DuckDB procesando tablas grandes (5 millones de filas) y pequeñas. El objetivo: medir tiempo de ejecución y uso de RAM en operaciones típicas de análisis de datos.
📊 Resultados destacados#
- ⚡ Polars fue la más rápida en casi todas las operaciones.
- 🧠 Pandas sigue siendo la más simple de usar y muy competitiva.
- 🐤 DuckDB brilla en consultas tipo SQL, pero mostró mayor consumo de memoria en transformaciones complejas cuando se le pide que escriba tablas. Pero mientras se utiliza el formato Arrow, es es más rápido.
🧩 Explicación en pocas palabras#
- Pandas → La librería clásica de Python para análisis de datos. Fácil, conocida, pero no la más rápida. Fácil escritura, lectura y debug.
- Polars → Una alternativa moderna escrita en Rust. Muy rápida y eficiente en memoria. La lectura de CSV, los groupbys y los joins suelen obtener las mayores mejoras.
- DuckDB → Un motor SQL embebido que permite trabajar con datos como si fueran tablas de base de datos. Útil cuando SQL resulta más claro que encadenar operaciones de DataFrames.
Si recién empezás, Pandas es el camino más amigable. Si buscás velocidad pura, Polars sorprende. Si buscas la máxima velocidad, ve con DuckDB.
Más información en el link 👇
Otros tests para considerar#

Más en la siguiente referencia externa.
También publicado en LinkedIn.
