🚀 dbt: the modern standard for building reliable data pipelines
In data engineering projects, dbt has become a key tool for transforming data in an organized, versioned, and scalable way.
Its proposition is simple but powerful: use SQL and software engineering best practices so teams can build clear, auditable, and easy-to-maintain data models.
✨ Why is it worth considering in a data engineering project?
- 🧩 True modularity: each transformation is an independent model that’s easy to test and reuse.
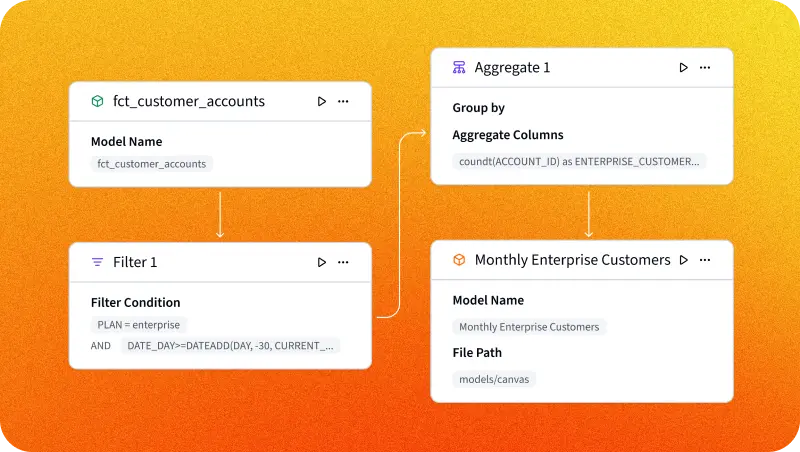
- 🔄 Automatic lineage: dbt generates the full dependency map, ideal for audits and troubleshooting.
- 🛡️ Built-in quality: it allows defining tests that validate data before it reaches production.
- ⚙️ CI/CD automation: it integrates with GitHub, GitLab, or Azure DevOps to run pipelines continuously.
- 📈 Scalability: it runs on major modern data warehouses (Snowflake, BigQuery, Redshift, Databricks).
🧪 Typical use cases in Data Engineering projects#
Data modeling for analytics
Building staging, intermediate, and mart layers for BI, dashboards, or ML models.Data governance and quality
Applying automated tests (uniqueness, integrity, expected values) to ensure reliability.Migration to a modern data warehouse
Standardizing transformations when moving from traditional ETL to an ELT approach.Living documentation of the data ecosystem
dbt generates navigable documentation with descriptions, tests, and lineage.Collaborative work between data engineers and analytics engineers
It unifies engineering practices with the simplicity of SQL.
🧠 In short#
If you’re getting started:
dbt is a tool that lets you transform data using SQL, but with the discipline of software development: versioning, testing, documentation, and automation.
Instead of having loose scripts, dbt organizes everything into a clean, reproducible project.
It’s like going from cooking without a recipe to having a complete cookbook where each step is clear, tested, and documented.
More information at the link 👇


