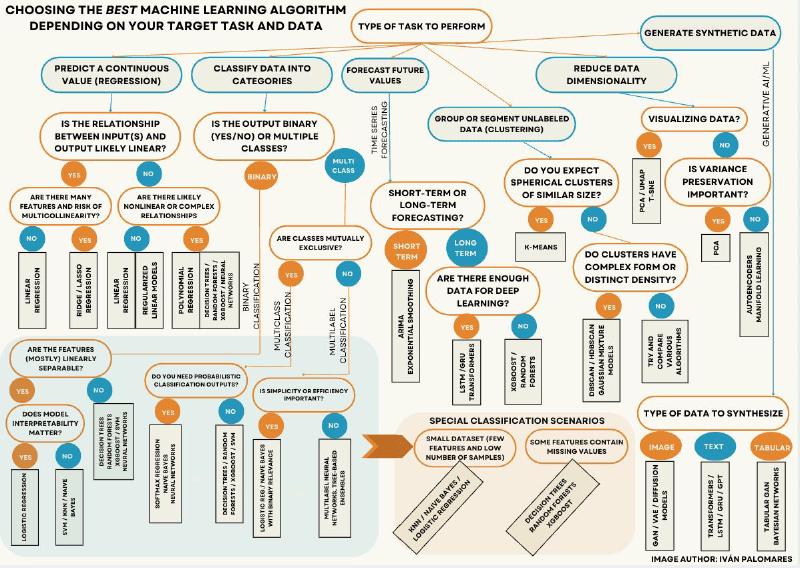
🌳 Which Machine Learning algorithm should you choose? Choosing the right ML algorithm isn’t always straightforward.
This KDnuggets article proposes a very visual approach: using a decision tree to guide the selection process based on the type of problem and the data available.
Key points of the approach:
Define your primary goal
- Do you want to classify, predict numeric values, cluster, or reduce dimensionality?
- The nature of the problem determines the initial branch of the tree.
Consider the size and type of data
- A small amount of structured data → classic algorithms like Logistic Regression or SVM.
- Lots of data or unstructured data → more complex models like Random Forest, XGBoost, or Neural Networks.
Weigh interpretability vs. accuracy
- If you need to explain decisions (e.g., in finance or healthcare), decision trees and linear models are clearer.
- If you’re aiming for maximum accuracy and can sacrifice explainability, choose ensembles or deep learning.
Iterate and validate
- Even with a good guide tree, testing multiple models and evaluating with cross-validation remains best practice.
💡 A decision tree for choosing algorithms doesn’t replace experimentation, but it speeds up focusing on the most promising options.
More information at the link 👇

Also published on LinkedIn.
